
I found out about Hoarder via the self-hosted podcast. While I don’t always agree with the opinions of the hosts, they’ve helped me discover useful things a few times. I’d certainly recommend checking the podcast out.
The Bookmark Everything App
Quickly save links, notes, and images and hoarder will automatically tag them for you using AI for faster retrieval. Built for the data hoarders out there!
The install is docker friendly and based on compose. It’s a very simple 3 steps to get a test instance setup.
- Download the compose yaml.
- Create a
.envfile with a few values - Then
docker compose up
Seems like it supports “sign up” – if you host this visibly externally you may have some spammy sign-ups.. this may be something you can disable.. (yes, you can disable this as I find out below)
After you have created a user – you are greeted with this blank canvas
 I currently run Wallabag – which I landed on after trying a few other choices. It was the best choice for my needs at the time, but also super basic. Wallabag has a mobile app which I find useful – as it makes sharing links I find on mobile easy to my Wallbag install.
I currently run Wallabag – which I landed on after trying a few other choices. It was the best choice for my needs at the time, but also super basic. Wallabag has a mobile app which I find useful – as it makes sharing links I find on mobile easy to my Wallbag install.
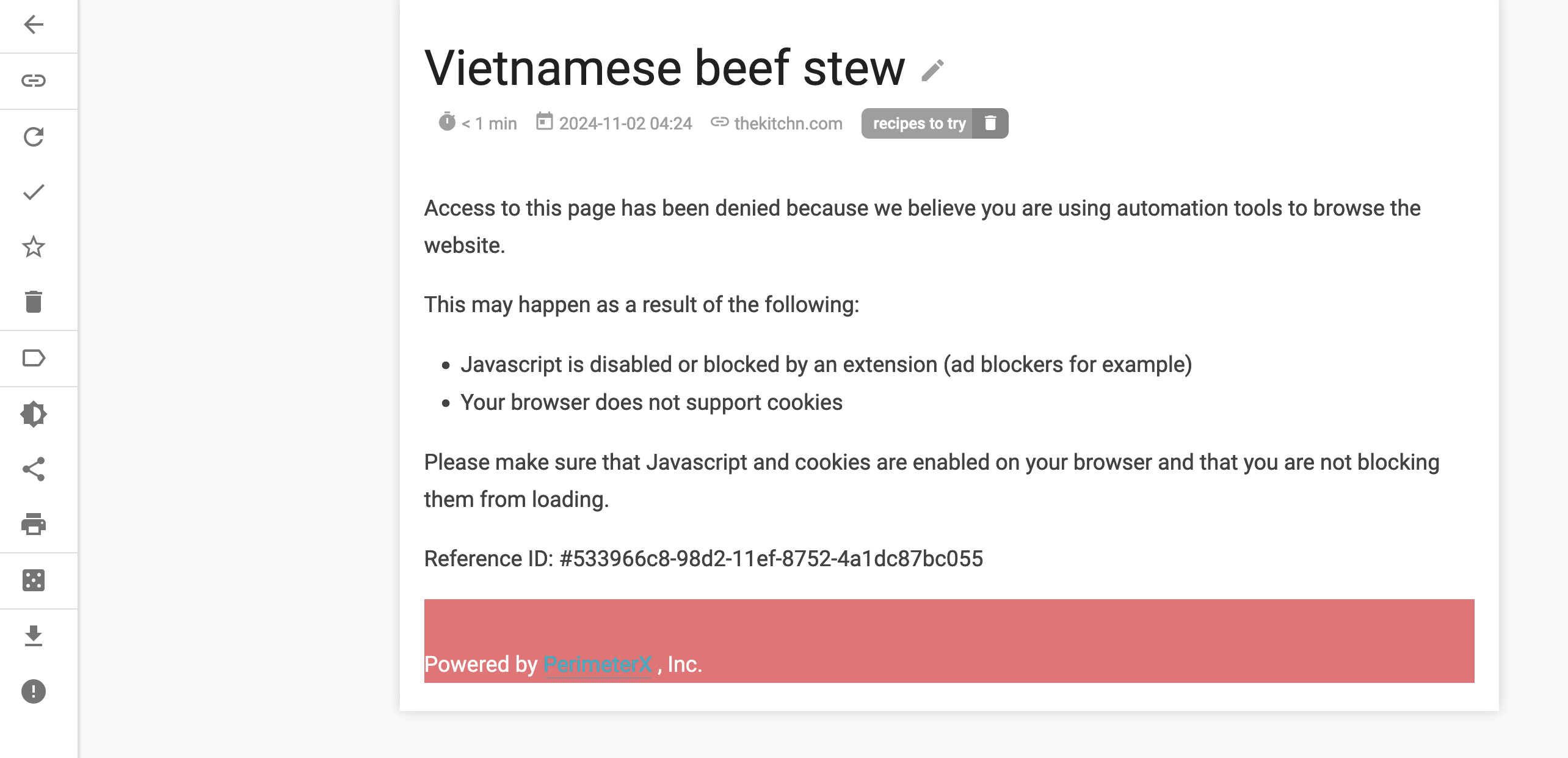
Wallabag often struggles to capture a page – but it at least keeps the link. One example is this website – which has some sort of scraper blocker. You get a page that indicates it is protected by this.
Ok – so how does Hoarder do with a link https://www.thekitchn.com/instant-pot-bo-kho-recipe-23242169?
For comparison – this is what wallabag got..
The capture in Hoarder take a bit of time – not long, but it renders sort of a blank-ish card immediately and then the image fills in.
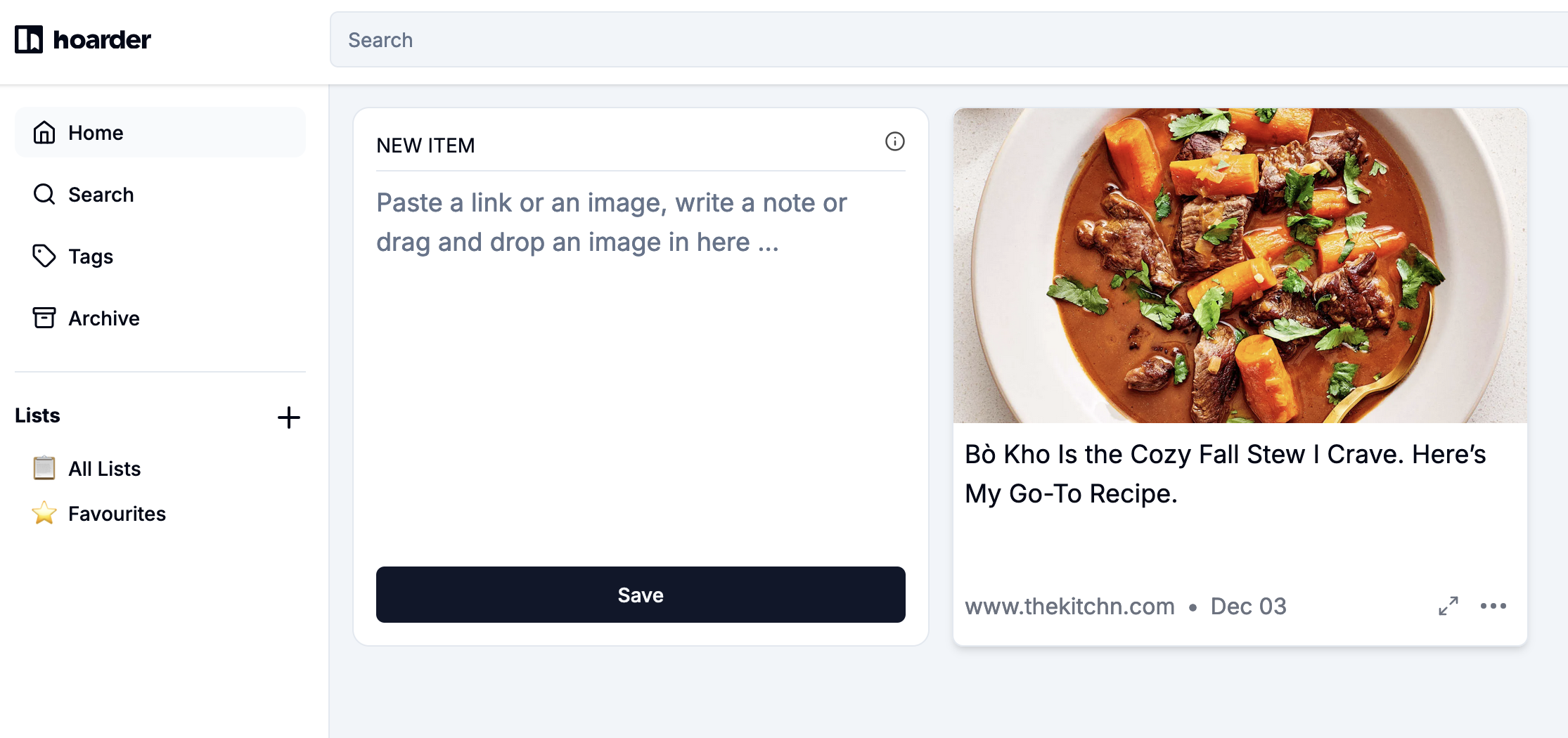
Let’s take a closer look at the tile that it created for me
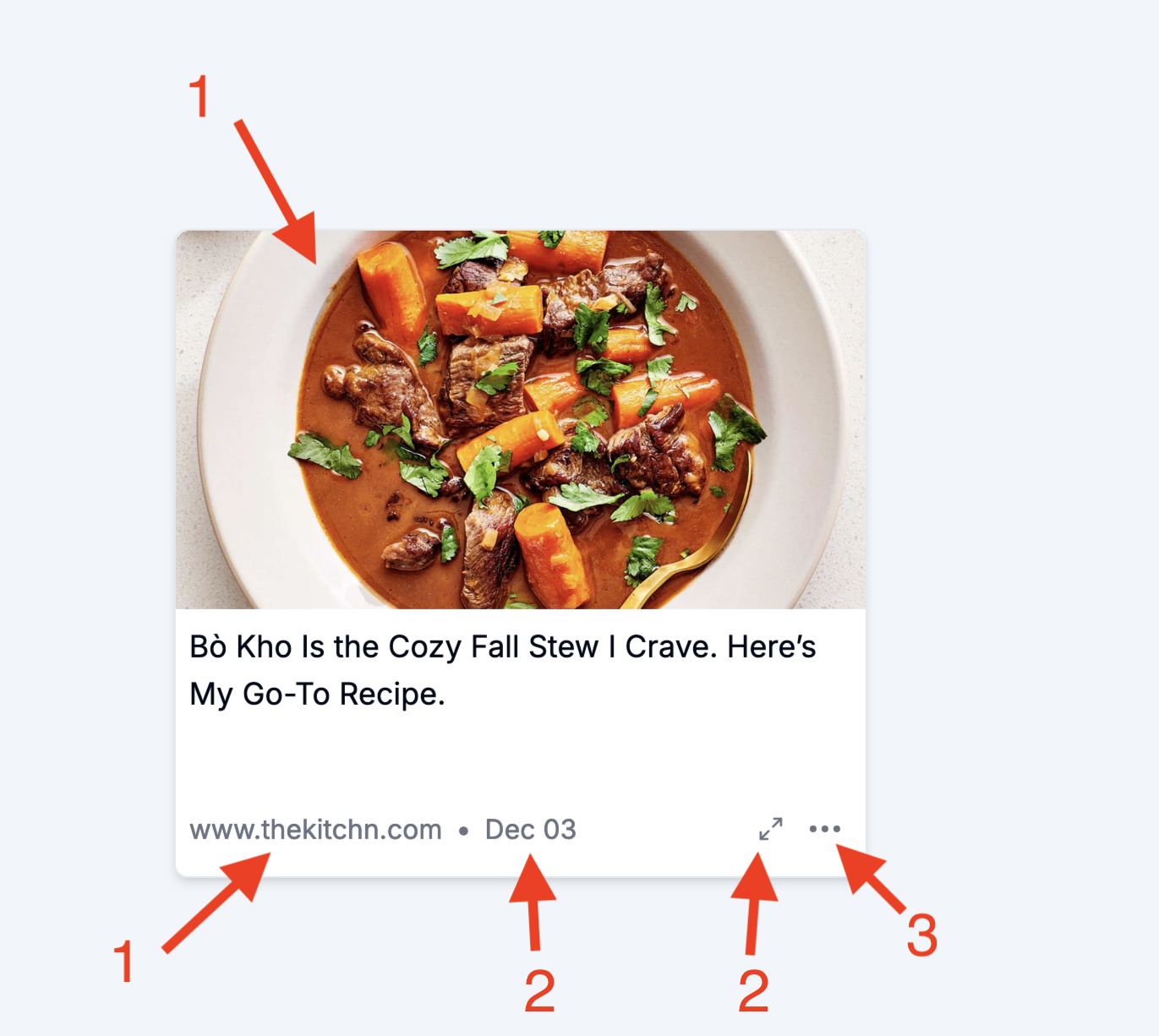
The top of the tile is a picture and link to the original URL (1). The link (1) is also the same destination.
The date (2) and expansion arrows (2) both take you to a larger locally hosted view.
(3) is a menu of options
Let’s dive deeper into the expanded (locally hosted view)
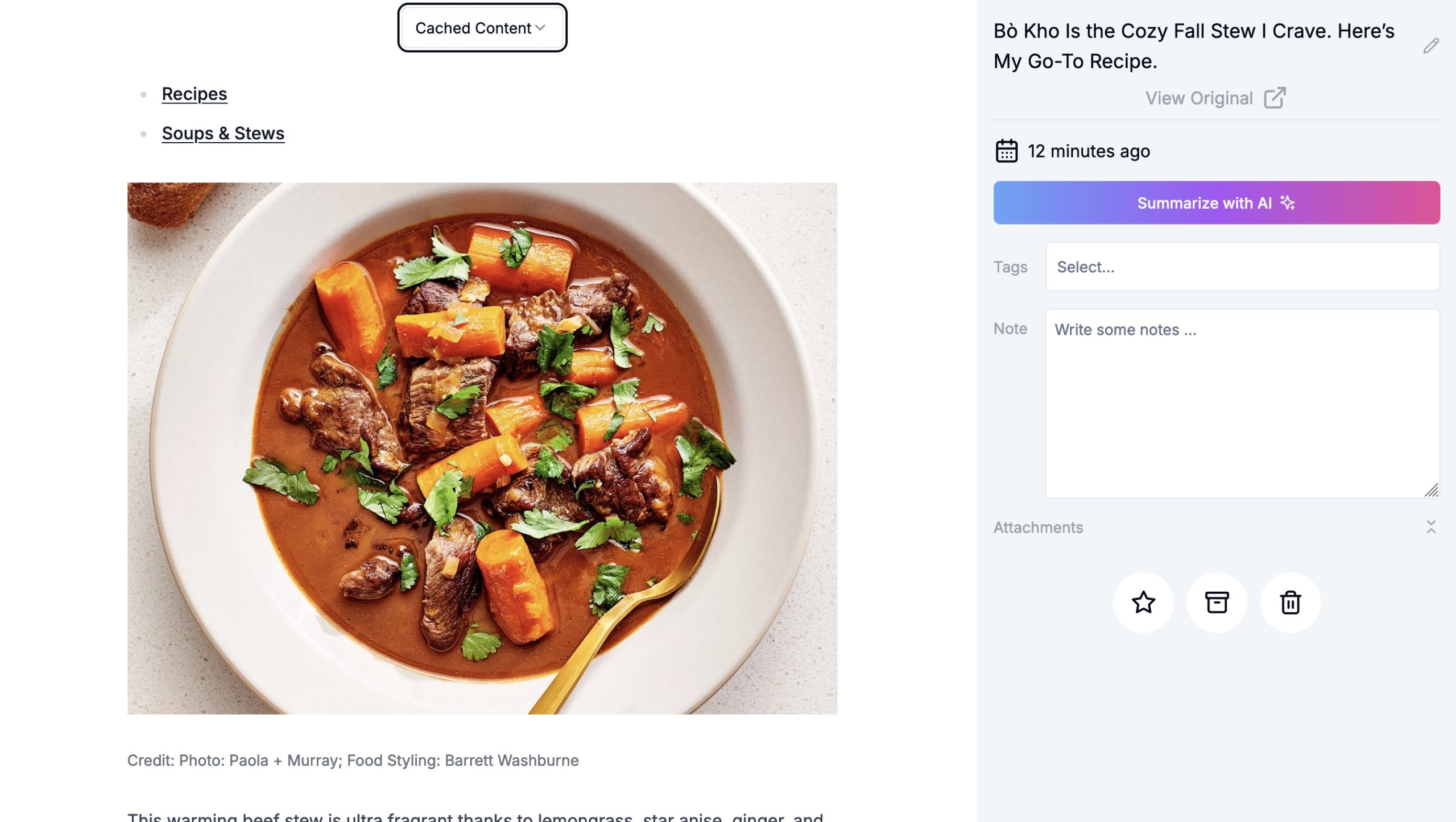
The overall capture/rendering of the page from the local version is pretty good. Links in the text haven’t been re-written, but that’s both expected and generally useful.

This view also offers the option to view a screenshot – which is as you expect.
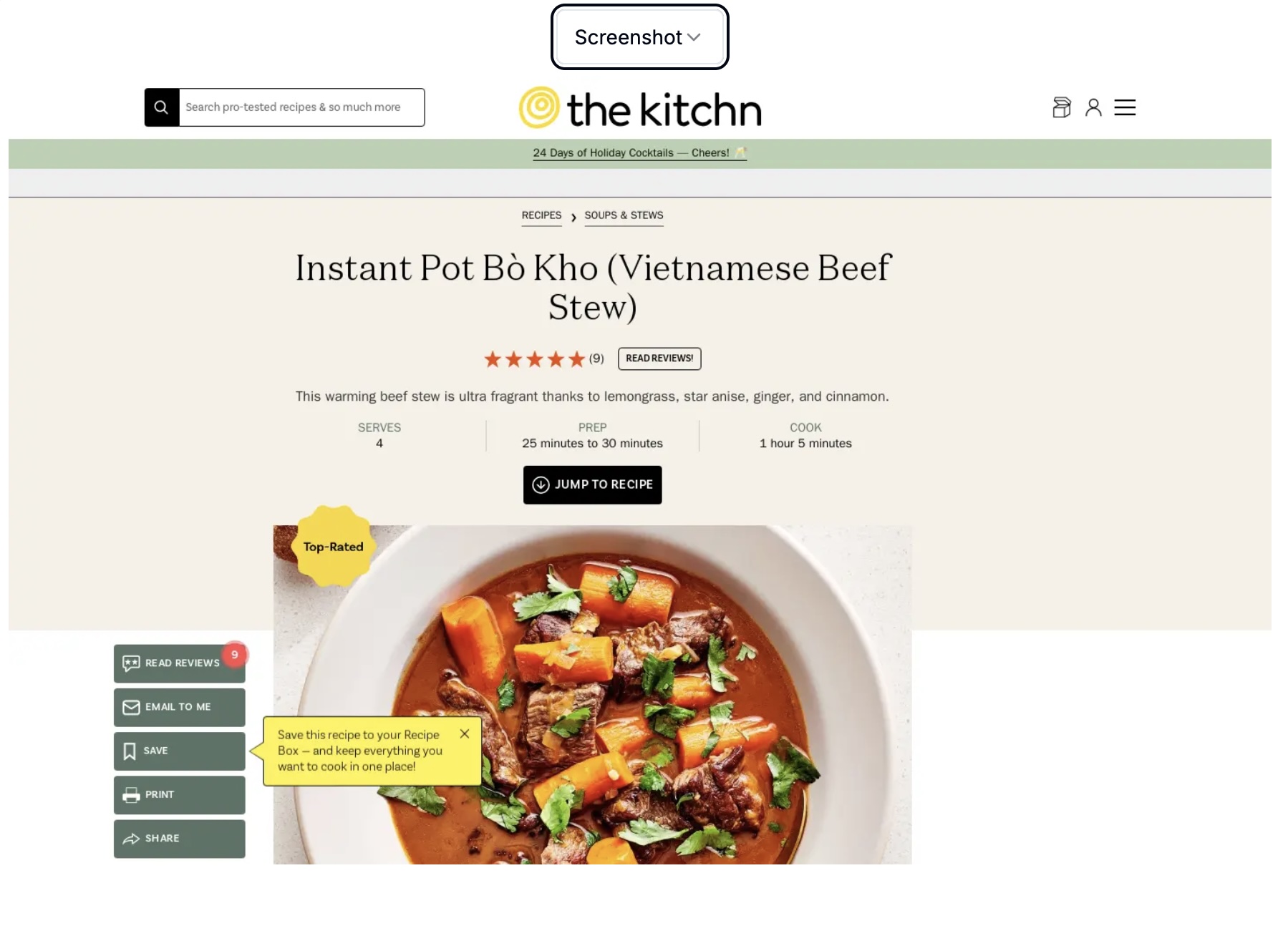
Since I didn’t provide an OpenAI key nor did I configure Ollama the fancy “Summarize with AI” button just gives me an error.
Looking – it seems this setup 3 unique containers
- ghcr.io/hoarder-app/hoarder:release
- getmeili/meilisearch:v1.11.1
- gcr.io/zenika-hub/alpine-chrome:123
but.. I’m not seeing any storage on the host – this is probably bad, because that means at least one of these containers is stateful (and looking at the compose — there are two data volumes)
|
1 2 3 |
volumes: meilisearch: data: |
I have a preference of storing my data on the host filesystem as a volume mapping… maybe I’ll warm up to the whole docker volume thing, but it always feels like a big hack. (Read on and you’ll find that there is a way to avoid the storage concerns that I have here).
The search appears limited to the title only (boo) – tags are supported in search too.. but no deep searching within the text of the articles.
Looking more at the doc – persistence is something you can configure
DATA_DIR – “The path for the persistent data directory. This is where the db and the uploaded assets live.”
and it does appear you can stop signups from happening
DISABLE_SIGNUPS – “If enabled, no new signups will be allowed and the signup button will be disabled in the UI”
Interesting options for the crawler (disabled by default)
CRAWLER_FULL_PAGE_SCREENSHOT – “Whether to store a screenshot of the full page or not. Disabled by default, as it can lead to much higher disk usage. If disabled, the screenshot will only include the visible part of the page”
CRAWLER_FULL_PAGE_ARCHIVE – “Whether to store a full local copy of the page or not. Disabled by default, as it can lead to much higher disk usage. If disabled, only the readable text of the page is archived.”
CRAWLER_VIDEO_DOWNLOAD – “Whether to download videos from the page or not (using yt-dlp)”
Overall – I’m pretty impressed. I’m not sure I’m quite ready to dump wallabag, but this might become a project I tackle during the holiday break. That stew recipe is pretty amazing, absolutely worth trying.