I’m slowly getting to clearing out some of the old office stuff at home, and yes, I appear to still have some 3.5″ floppies. I did in fact have a 3.5″ floppy drive, but it was in an old husk of a former PC. My desktop machine has a modern power supply and didn’t even have the right power connector to hook up the drive (easy fix with an adapter) – at least the motherboard still had the right connector to hook up the data cable.
I’m slowly getting to clearing out some of the old office stuff at home, and yes, I appear to still have some 3.5″ floppies. I did in fact have a 3.5″ floppy drive, but it was in an old husk of a former PC. My desktop machine has a modern power supply and didn’t even have the right power connector to hook up the drive (easy fix with an adapter) – at least the motherboard still had the right connector to hook up the data cable.
I then had to do the right BIOS dance to actually enable the device, once this was done I could see it under Linux as /dev/fd0. Unfortunately the handful of disks I tried to mount gave errors, it seemed either this drive is faulty or all of my disks are expired. Now, these are floppies from the early 90’s – which is oh my 35 years ago!
Time to bust out ddrescue, and see if I can image any of these disks to pull data. Sadly my initial attempts were not great – I wasn’t getting much data off of these at all. Maybe this is a huge waste of time. I found the useful seeming ddrescueview which gives me a way to look at the status of the rescue attempt.
Let’s cover the basics. My initial attempts looked like
|
1 |
ddrescue /dev/fd0 floppy.fd floppy.map |
This worked, but I got a lot of errors. Adding the -d flag seemed to help a lot, but later I found out that I needed more flags to make this right.
|
1 |
ddrescue -d /dev/fd0 floppy1.fd floppy1.map |
I found a useful wikipage entry from the archiveteam specific to recovering floppies.
Here is the ddrescueview visualization of my initial attempt:
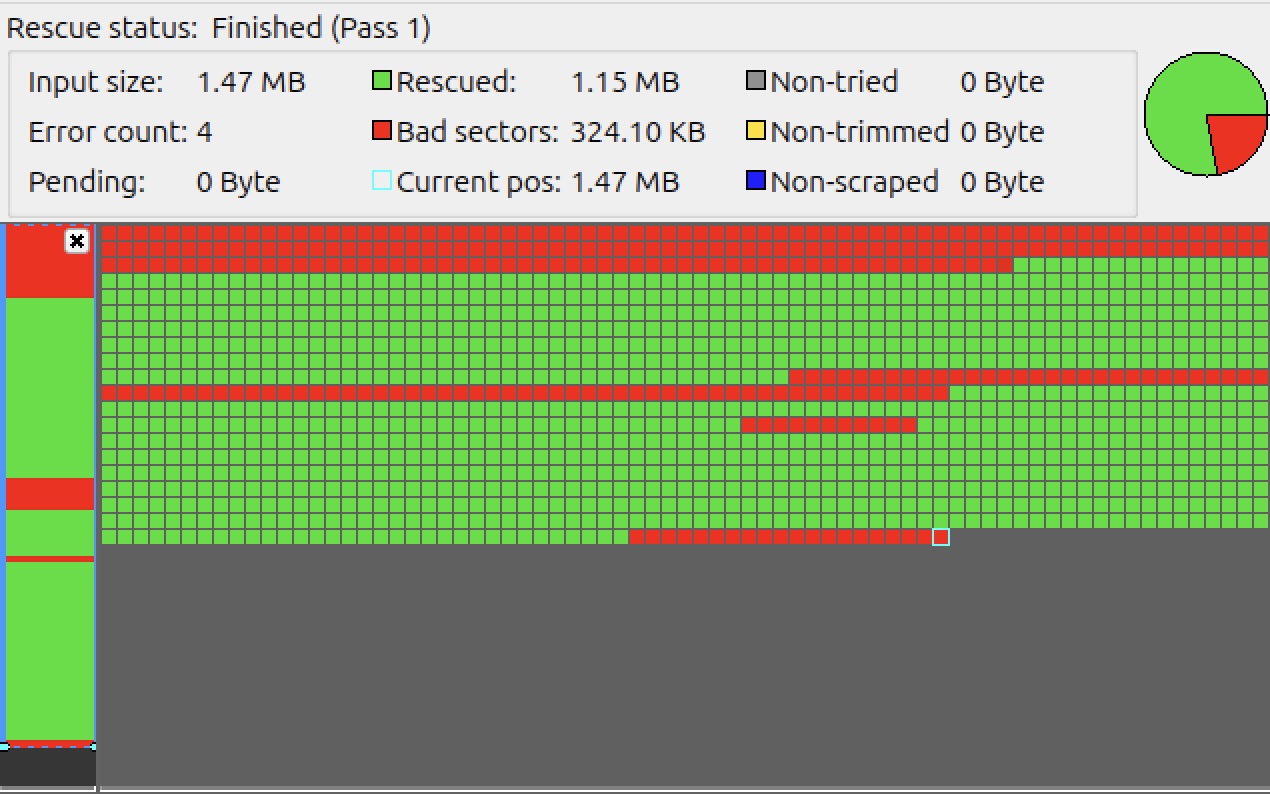 So not great. Next up is when I added the
So not great. Next up is when I added the -d flag
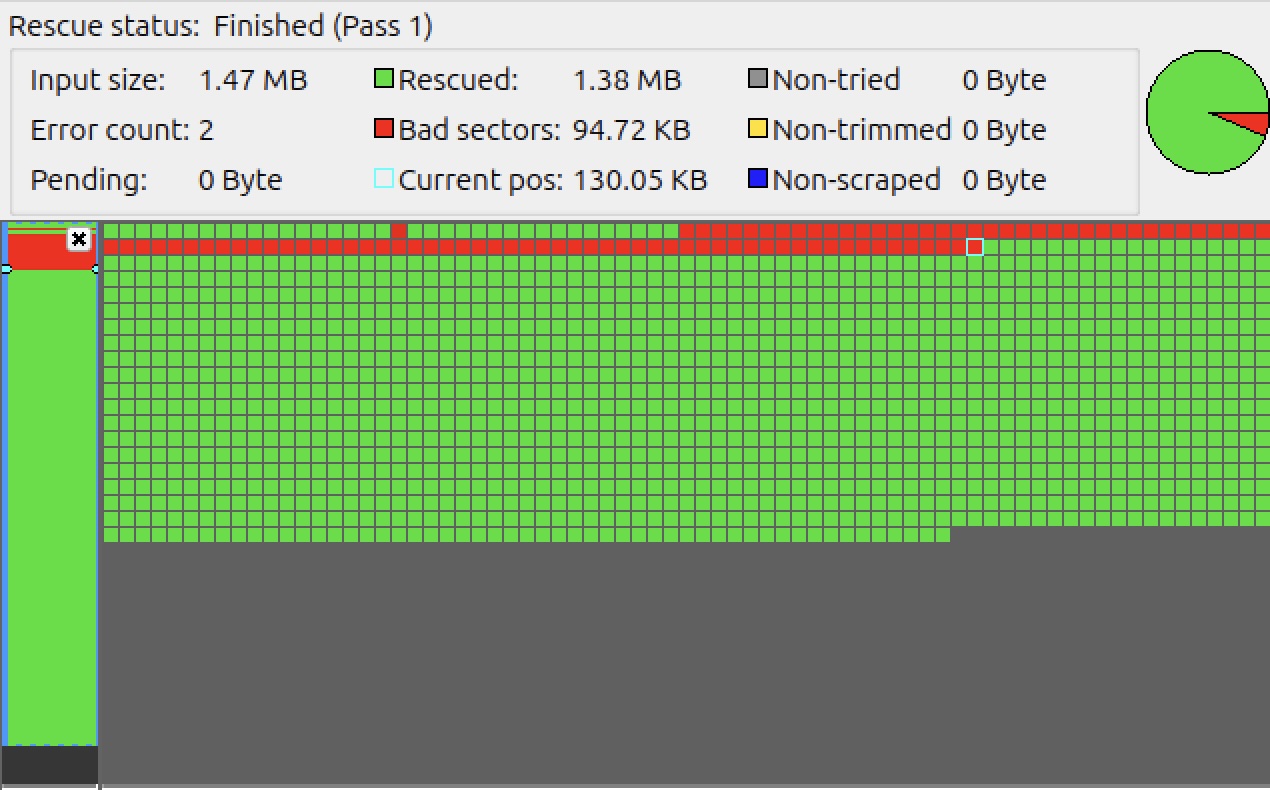 Better. Of course as I decided to make sure this was repeatable, I tried removing the
Better. Of course as I decided to make sure this was repeatable, I tried removing the -d flag and running it again to make sure it was really bad. This time I got a completely clean read (fully green). There were 2 errors reported, but it retried and it was good?
So I start trying various combinations to see if I’m getting repeatable results. Overall it’s random errors and no clean reads again.
Now the clever thing that ddrescue does, is maintain a map file. This captures what was done, and allows you to run another pass to try to have more luck. This is what I need. Referencing the archiveteam advice I landed on this as the right combination
|
1 |
ddrescue -d -b512 -r 3 --retrim /dev/fd0 floppy3.fd floppy3.map |
Let’s break down the flags
- -d : direct access
- -b512 : sector size of 512 bytes, important for direct access
- -r 3 : retry errors 3 times
- –retrim : allows us to re-run, and re-try failed blocks in the map
Using this magic, I was able to run the command a second time and get a clean read! So you can either be lucky, or use the map file and try a few times with the right settings.
Now I can mount the image under linux
|
1 |
sudo mount -o loop ./floppy3.fd /mnt |
This particular floppy apparently contained a few rescue tools (NDD.exe ring any bells) Well, glad I got those bits back – guess I’ll toss it on the pile and move on to the next one.
Now that I have things sorted out – I’m finding a couple that read clean, which is pretty cool given the files are from 1991. Amazing how little fits on these floppies, when it used to seem like so much.
I did manage to ‘crash’ the floppy drive with bad disks or something, because it would get into a state that rebooting the machine would not fix. Powering it off for a minute or two and a full cold boot seemed to get things back on track. When it was busted I’d get errors like:
|
1 |
ddrescue: /dev/fd0: Can't open input file: No such device or address |
I did run into more problems just like this and I really don’t understand what was wrong, or how to get it to behave again. Very frustrating. I just had to keep trying cold boots and different floppies. Looking at dmesg I see:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
[126665.905377] floppy0: probe failed... [126666.305674] floppy0: probe failed... [126666.705767] floppy0: probe failed... [126667.106039] floppy0: probe failed... [126667.506158] floppy0: probe failed... [126667.906413] floppy0: probe failed... [126668.306554] floppy0: probe failed... [126668.706758] floppy0: probe failed... [126669.106971] floppy0: probe failed... [126669.507257] floppy0: probe failed... [126669.907348] floppy0: probe failed... [126670.307625] floppy0: probe failed... [126670.707695] floppy0: probe failed... [126671.107969] floppy0: probe failed... [126671.508020] floppy0: probe failed... [126671.908307] floppy0: probe failed... [126671.908318] I/O error, dev fd0, sector 0 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 2 [126671.908329] floppy: error 10 while reading block 0 |
I picked up a used USB floppy drive locally, it was only $15 and it gave me a secondary device to try some of these floppies with — and I was hitting my head against the wall with the errors above.
 The USB floppy appears on my system as a drive
The USB floppy appears on my system as a drive /dev/sdc – but I can just use that device in place of /dev/fd0 and the same commands work. Hopefully resetting the state will be easier as I can just unplug the USB drive and try it again. We’ll see if it gets into a similar busted state (which appears to be triggered by bad reads). So far it seems much more stable overall and I’m working my way through my old floppies.
The USB floppy drive worked really well. It is starting to seem like that old 3.5 floppy drive I installed in my machine was maybe not so stable. Some floppies that had many errors, read just fine with the USB floppy drive.
To speed things up, I adopted a two phased approach. Trying an optimistic version which would fail out quickly – followed by the more aggressive 3 retry version above if I determined I wanted to get as much data as possible. This is the quick version:
|
1 |
ddrescue -d -b512 -n /dev/fd0 floppy.fd floppy.map |
As a bonus for anyone who’s hung on this far into the post, let me share some of the output you get from the ddrescue tool showing the progress it makes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
$ sudo ddrescue -d -b512 -r 3 --retrim /dev/fd0 floppy.fd floppy.map GNU ddrescue 1.28 Press Ctrl-C to interrupt ipos: 1441 kB, non-trimmed: 32768 B, current rate: 0 B/s opos: 1441 kB, non-scraped: 0 B, average rate: 25746 B/s non-tried: 0 B, bad-sector: 0 B, error rate: 4096 B/s rescued: 1441 kB, bad areas: 0, run time: 56s pct rescued: 97.77%, read errors: 1, remaining time: 2s time since last successful read: 8s Copying non-tried blocks... Pass 1 (forwards) ipos: 1474 kB, non-trimmed: 0 B, current rate: 0 B/s opos: 1474 kB, non-scraped: 31744 B, average rate: 22885 B/s non-tried: 0 B, bad-sector: 1024 B, error rate: 128 B/s rescued: 1441 kB, bad areas: 2, run time: 1m 3s pct rescued: 97.77%, read errors: 3, remaining time: n/a time since last successful read: 15s Trimming failed blocks... (forwards) ipos: 1473 kB, non-trimmed: 0 B, current rate: 0 B/s opos: 1473 kB, non-scraped: 0 B, average rate: 5482 B/s non-tried: 0 B, bad-sector: 32768 B, error rate: 170 B/s rescued: 1441 kB, bad areas: 1, run time: 4m 23s pct rescued: 97.77%, read errors: 65, remaining time: n/a time since last successful read: 3m 35s Scraping failed blocks... (forwards) ipos: 1474 kB, non-trimmed: 0 B, current rate: 512 B/s opos: 1474 kB, non-scraped: 0 B, average rate: 2979 B/s non-tried: 0 B, bad-sector: 30720 B, error rate: 0 B/s rescued: 1443 kB, bad areas: 1, run time: 8m 4s pct rescued: 97.91%, read errors: 125, remaining time: 15m time since last successful read: 0s Retrying bad sectors... Retry 1 (forwards) ipos: 1441 kB, non-trimmed: 0 B, current rate: 0 B/s opos: 1441 kB, non-scraped: 0 B, average rate: 2704 B/s non-tried: 0 B, bad-sector: 6144 B, error rate: 128 B/s rescued: 1468 kB, bad areas: 1, run time: 9m 3s pct rescued: 99.58%, read errors: 137, remaining time: 6s time since last successful read: 44s Retrying bad sectors... Retry 2 (backwards) ipos: 1447 kB, non-trimmed: 0 B, current rate: 2048 B/s opos: 1447 kB, non-scraped: 0 B, average rate: 2601 B/s non-tried: 0 B, bad-sector: 2048 B, error rate: 0 B/s rescued: 1472 kB, bad areas: 1, run time: 9m 25s pct rescued: 99.86%, read errors: 141, remaining time: 5s time since last successful read: n/a Retrying bad sectors... Retry 3 (forwards) Finished $ sudo ddrescue -d -b512 -r 3 --retrim /dev/fd0 floppy.fd floppy.map GNU ddrescue 1.28 Press Ctrl-C to interrupt Initial status (read from mapfile) rescued: 1472 kB, tried: 2048 B, bad-sector: 0 B, bad areas: 0 Current status ipos: 1443 kB, non-trimmed: 0 B, current rate: 1536 B/s opos: 1443 kB, non-scraped: 0 B, average rate: 1024 B/s non-tried: 0 B, bad-sector: 0 B, error rate: 0 B/s rescued: 1474 kB, bad areas: 0, run time: 1s pct rescued: 100.00%, read errors: 0, remaining time: 0s time since last successful read: n/a Trimming failed blocks... (forwards) Finished |
You can see above, that it did in fact get to 100%, but slowly and required a secondary run to finish.
This was certainly a trip down memory lane, I’m glad I persisted in trying to read the data. There were a few files I wanted to keep out of the pile of floppies, and now I’ve got the archived with my other files to keep.